A Tour of Go 小记
2019-12-23
周末花了两个下午把 go 的官方 quick start 小册子 A Tour of Go[1] 刷完了,内容以及练习本身不算难,不过也是有很多细节, 另外里面会有很多官方博客的 ref,是宝藏了。
Basics
Packages
- 包名是 import path 的最后一段的值,比如
fmt和fmt、rand和math.rand - 以大写字母开头的变量、函数可以在包外访问,比如
math.Pi
Functions
- 函数的参数类型跟在变量名后面
- 多个同类型的参数可以共享最末尾的类型声明
(x int, y int) => (x, y int) - 函数可以有多个返回值
- 函数可以返回命名返回值(尽量用于短函数)
func add(x int, y int) int {
return x + y
}
这里给了一篇文章讲 go 的声明语法为啥是这样。
首先先讲了 c 语言的语法,比如 int x; 表示 the expression 'x' will have type int, 这里的意思是包含变量的表达式求值能得出一个基本类型,
然后把类型放在左边,表达式放在右边即为一个声明,给了几个例子
- int *p; # 声明一个指向 int 的指针 p
- int a[3]; # 声明一个长度为 3 的 int 数组
- int main(int argc, char argv[]) { / … */ } # 声明一个返回 int 的名为 main 的函数
不过遇到函数指针这样的写法的话,可读性就比较差了,一个经典的例子是下面这个
- int (*fp)(int a, int b);
- int (fp)(int (ff)(int x, int y), int b)
如果考虑把参数名去掉,再去看的话,就更难以理解
- int (*)(int, int)
- int (fp)(int ()(int, int), int)
- int ((fp)(int (*)(int, int), int))(int, int)
(这里我猜作者应该是考虑到函数式编程的那种写法,比如像 scala 里的这种函数类型参数 f: (SparkSession, String, String, Int) => Option[String] ,避免以后埋坑)
另外这里也提到了,为啥 c 里面类型转换是 (int)M_PI 括号括在类型上这种形式,因为如果括在变量上的话就和上面👆那种写法冲突了,比如 c 里这样的写法是合法的
#include <stdio.h>
int(main(void)) {
printf("Hello World2\n");
return 0;
}
go 的声明语法是从左向右读的,也就是 x 有一个类型 y,所以不管是变量还是函数都有这样的语法
- x int
- p *int
- a [3]int
- func main(argc int, argv []string) int
如果用上面 c 语言的例子,去掉变量名也不影响可读性
- func main(int, []string) int
- f func(func(int,int) int, int) int
- f func(func(int,int) int, int) func(int, int) int
不过文中也说了指针的语法是个例外,因为一开始和 c 绑的有点紧,所以有时候会用上各种括号来表达明确的含义。
anyway,他们觉得比 c 的类型语法是要好很多的(不过我觉得锅全在指针这儿。。。。)
Variables
- var 语句可以声明一个或多个变量
var i int或者var c, python, java bool - var 语句的可以是 package 或者 function 级别
- var 语句也可以声明初始值(可以略去类型),比如
var c, python = true, false - 仅在函数/方法内部可以用
c := true这种写法替换👆的var初始值声明
Basic Types
- bool
- string
- int int8 int16 int32 int64
- uint uint8 uint32 uint64 uintptr
- byte //alias for uint8
- rune //alias for int32, represents a Unicode code point
- float32 float64
- complex64 complex128
另外 int、uint、uintptr 在 32 位系统是 4 字节长,在 64 位系统是 8 字节长,除非特殊原因,在声明一个整型数应该永远使用 int
另外 %T %v 表示类型和值
- 数字类型的零值是 0
- 布尔类型的零值是 false
- 字符串类型的零值是
""
类型转换表达式 T(v) 表示把值 v 转换为 T 类型
Type inference
当变量声明没有明确的指定类型,变量类型则可从等号右边的值推断出来
Constants
- 常量声明有
const关键字修饰 - 常量声明不能用
:=语法 - 数字类型的无类型常量类型由上下文决定(常量当参数传入会根据参数类型做类型转换)
const Pi = 3.14
For/If
go 只有一种循环控制语句 for, 和 c 的基本一致,如下
sum := 0
for i := 0; i < 10; i++ {
sum += i
}
for的三个语句外没有括号,并且执行语句永远有大括号{}- 初始语句和后置语句是可选的(以及它们的分号)
- 去掉条件语句就变成了死循环
for {} if条件不需要括号,执行语句得有大括号{}, 和for基本一致if可以跟一个短声明,在条件语句(短声明里的变量作用域仅在 if 内)
func pow(x, n, lim float64) float64 {
if v := math.Pow(x, n); v < lim {
return v
}
return v
}
Exercise: Loops and Functions
练习,牛顿法求开平方,本科最优化课的时候学过,不过忘差不多了23333333
开平方的推导过程相当于求函数 的值, 这里 就是被开平方数的值,
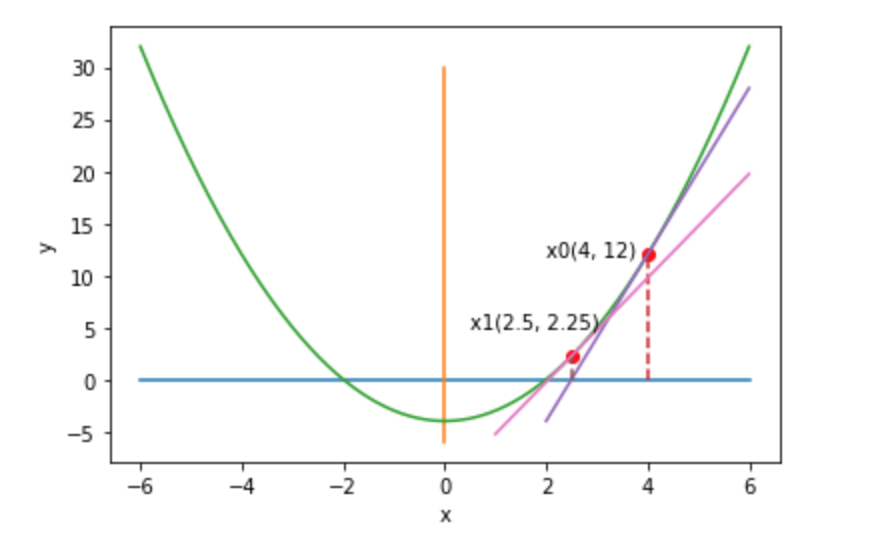
这里给了一张 的图(画图用的不好参考的 v2 上的一篇文章)
目的是求函数与 轴的交点,任取一点作切线,切线斜率则为 的导数,从 作到 轴的垂线围成的直角三角形可得
即
化简得
多次计算,达到一定精度,则可求出交点值
package main
import (
"fmt"
"math"
)
func Sqrt(x float64) float64 {
z := 1.0
for math.Abs(z*z - x) > 0.0001 {
z = (z+x/z)/(2)
}
return z
}
func main() {
fmt.Println(Sqrt(2))
}
Switch
- 每个 case 末尾会自动加上 break 语句
- switch 的 case 语句可以是表达式
- switch 后的表达式也是可选的(这样和 if-then-else 作用一样)
- switch 求值顺序是从上到下
Defer
- 跟在
defer后的语句会在函数返回后执行 (上下文关闭功能) - defer 调用的参数是立刻求值的
- 多个 defer 按栈顺序求值
这里有一篇文章[3]讲了 Defer 的实现
defer 声明会把函数调用推到栈里去,在函数返回后,在对这个栈进行 pop 求值
不过我觉得 python 那种 with 形式看着比较干净,这里为啥用 defer 拉平可能是因为 go 格式化用两个 tab,每个 tab 四个空格,用 with 的话可能 ide 都放不下了。。。。
除了上面的三点,还有一点要注意 Deferred functions may read and assign to the returning function's named return values.
func c() (i int) {
defer func() { i++ }()
return 1
}
这里返回的应该是 2
Pointers
- 类型
*T表示一个指向类型T的值的指针,指针类型的零值是 nil &符号生成一个指向操作数的指针*符号指向指针引用的值- go 没有指针运算
package main
import "fmt"
func main() {
i, j := 42, 2701
p := &i // point to i
fmt.Println(*p) // read i through the pointer
*p = 21 // set i through the pointer
fmt.Println(i) // see the new value of i
p = &j // point to j
*p = *p / 37 // divide j through the pointer
fmt.Println(j) // see the new value of j
}
Struct
- 可以通过结构体指针访问结构体字段(有
v := Vertex{1, 2}; p:= &v,则(*p).X写做p.X)
package main
import "fmt"
type Vertex struct {
X int
Y int
}
func main() {
v := Vertex{1, 2}
v.X = 4
fmt.Println(v.X)
}
Array
- The type
[n]Tis an array ofnvalues of typeT. 如var a [10]int - 数组是定长的
- array literal:
[3]bool{true, true, false}
Slices
- The type []T is a slice with elements of type T.
- slices 是不定长的,
a[low: hight]左闭右开,边界有默认值 - slices 不存储数据,只对关联的数组做范围引用(所以多个 slice 引用同一个数组,改变均可见)
- slice literal: []bool{true, true, false}
- slice 的零值是 nil,len 和 cap 均为 0 且无关联数组
- slice 可以套娃
- length 表示当前 slice 引用的元素个数
- capacity 表示 slice 关联的数组从 slice 第一个元素向后计数的元素个数
- len(s), cap(s)
- 可以使用 make 创建 slice:
b := make([]int, 0, 5) // len(b)=0, cap(b)=5 - append 函数用来向 slice 增加新元素(如果底层关联的数组放不下这些元素则会重新分配内存,返回一个新的 slice)
这里有一篇文章[4]讲 slice 的使用和内部实现
slice 建立在 array 上,所以先从 array 说起,go 的 array 声明确定了数组的大小和类型,默认值则为对另类型的零值, 需要注意的是,go 的数组变量表示整个数组,不是 c 里面那种表示首元素指针的形式,也就是说把数组变量赋值给其他变量或者 当值参数传来传去就会产生数组复制(当然也可以传数组指针来规避,但是也只是指针而不是数组),所以最好把数组理解为一个仅有索引而无字段的定长的一系列同类型值的结构体
这样看,array literal 的写法就很清晰了
b := [2]string{"Penn", "Teller"}
切片操作不会复制数据,只会创建一个新的 slice,不过也有一点不好的是如果只引用了一小部分数据,但整个底层数组的数据也会一直在内存里,
所以如果对数据规模有了解的话,可以在这种情况下使用下 copy 或者 append 来规避这个事情。
Range
- range 可以迭代
slice/map - 迭代
slice会返回 index 和 copy of the element
Maps
- map 的零值是 nil
- 可以用 make 创建 map:
m := make(map[string]int) - Map literals 和 struct literals 基本一致,key 是必填项
- 判断元素在不在:
elem, ok := m[key] - 删除元素:
delete(m, key)
Exercise: Maps
- wordCount,没什么难度,go 有个
strings.Fields这个函数可以用来分割字符串
Function values
- 函数也是值,可以当作参数传递
Function closures
closure 的定义是函数类型的值引用了该函数体外的变量,该函数可以访问和变更引用的变量,所以闭包这个包的概念就是把函数体外的变量用一个袋子和这个函数套在一起了,
闭包内的变量是独立的,多个闭包之间无关联,给了一个例子,配合单步调试效果更明显:
package main
import "fmt"
func adder() func(int) int {
sum := 0
return func(x int) int {
sum += x
return sum
}
}
func main() {
pos, neg := adder(), adder()
for i := 0; i < 10; i++ {
fmt.Println(
pos(i),
neg(-2*i),
)
}
}
Exercise: Fibonacci closure
练习是用闭包求 Fibonacci 数列,也比较简单
package main
import "fmt"
// fibonacci is a function that returns
// a function that returns an int.
func fibonacci() func() int {
a, b := 0, 1
return func() int {
a, b = a + b, a
return b
}
}
func main() {
f := fibonacci()
for i := 0; i < 10; i++ {
fmt.Println(f())
}
}
Methods and interfaces
Methods
- go 没有 class 的概念,类上的方法可以用
methods on types来实现 - 方法是带有 receiver 参数的函数,
func (v Vertex) Abs() float64 - type 可以不需要定义 struct,比如类型别名
type MyFloat float64 - ⚠️:只能定义 receiver 对应的类型在同一个 package 内的方法
- 带
pointer receiver的方法可以更改 receiver 指向的值 - 也就是一个传引用,一个传值
- 函数的指针参数需要传指针过去,而带
pointer receiver的方法会自动把值引用变成指针引用,也就是v.Scale(5) -> (&v).Scale(5) - 函数的值参数必须传入对应的类型,而带
value receiver的方法会自动把从地址取值,也就是p.Abs() -> (*p).Abs()
用 pointer receiver 的理由
- 可以修改值
- 函数调用的时候防止复制数据
- 另外尽量不要混用这两种写法
Interfaces
- An interface type is defined as a set of method signatures.
- 接口类型的值可以是任意一个实现了该接口定义的方法的值
- 类型实现接口方法是隐式的,不需要 implements 这种语句
- 接口值可以认为是
(value, type)二元组(这里是 concrete type) - 如果该类型值是 nil,方法调用则有一个 nil receiver
- nil interface 的值和类型都是 nil
- 空接口就是没有定义方法的接口
interface{} - 每个类型都实现了空接口,可以用来处理不确定类型的参数,比如
fmt.Print的实现
Type assertions
- 用来检查接口值是否和期待的类型匹配:
t, ok := i.(T)
Type switches
- 匹配类型的 switch
switch v := i.(type) {
case T:
// here v has type T
case S:
// here v has type S
default:
// no match; here v has the same type as i
}
Stringers
- 实现
String方法即可定制fmt.Println函数输出
Exercise: Stringers
定制输出 ip 地址对象,这里注意 int 字面值转 string 要用 strconv.Itoa 函数
Errors
error 类型的实现如下
type error interface {
Error() string
}
Exercise: Errors
之前开平方根的程序增加对负数的处理,也没什么难度,这里注意 fmt.Sprintf 是有一个 string 类型的返回值的
Readers
io.Reader 接口有一个 Read 方法
func (T) Read(b []byte) (n int, err error)
Read 方法自动把数据填充到给定的 byte 类型切片然后返回这次填充的数据大小和 error 值,当流结束则返回 io.EOF error
Exercise: Readers
实现一个生成无限 A 的流,也比较简单,填就行了
package main
import "golang.org/x/tour/reader"
type MyReader struct{}
// TODO: Add a Read([]byte) (int, error) method to MyReader.
func (r MyReader) Read(b []byte) (n int, err error) {
n = 0
err = nil
for idx := range b {
b[idx] = 65
n += 1
}
return
}
func main() {
reader.Validate(MyReader{})
}
Exercise: rot13Reader
实现一下 rot13 编码,翻了翻文档不算难,这里要注意溢出,以及对空格的处理(这里我偷懒了。。。)
package main
import (
"io"
"os"
"strings"
)
type rot13Reader struct {
r io.Reader
}
func (rot rot13Reader) Read(p []byte) (n int, err error) {
n, err = rot.r.Read(p)
if err == io.EOF {
return
}
for i := 0; i < n; i++ {
if p[i] > 109 {
p[i] -= 13
} else {
p[i] += 13
}
}
return
}
func main() {
s := strings.NewReader("Lbh penpxrq gur pbqr!")
r := rot13Reader{s}
io.Copy(os.Stdout, &r)
}
Concurrency
Goroutines
- goroutine 是 go 运行时的一种轻量级
线程,go f(x, y, z) x,y,z的求值发生在当前 goroutine, 函数 f 的执行发生在新的 goroutine- goroutine 共享内存,所以访问同一块资源需要加锁
Channels
- channel 用于 goroutine 之间通信
- 使用 make 创建:
ch := make(chan int) - channel 的发送和收取只有当对端准备好后才执行,否则一直阻塞(好处是不需要程序去用锁和条件变量进行同步)
Buffered Channels
- 可以设定带缓冲区的 channel:
ch := make(chan int, 100) - 当 buffer 满的时候,往 channel 的发送则阻塞,当 buffer 空的时候,channel 的读取则阻塞
Range and Close
- 关闭 channel 表示没有其他数据要发送了,receiver 可以通过判断 channel 是否关闭来确定是否还有其他数据
v, ok := <-ch for i:= range c这种写法会自动处理 channel 关闭的情况- 能且仅能 sender 可以关闭 channel
- channel 不属于文件那种系统资源,不关闭也不影响,除非需要关闭
fibonacci 用 goroutine 实现
package main
import (
"fmt"
)
func fibonacci(n int, c chan int) {
x, y := 0, 1
for i := 0; i < n; i++ {
c <- x
x, y = y, x+y
}
close(c)
}
func main() {
c := make(chan int, 10)
go fibonacci(cap(c), c)
for i := range c {
fmt.Println(i)
}
}
Select
- select 使 goroutine 在多个 channel 上等待执行
- 如果有 case 不能执行(channel 没数据), select 就会阻塞,否则则执行那个 case,多个 case 满足条件时随机选择执行
- 去除阻塞用 default case
带 quit channel 的 fibonacci
package main
import "fmt"
func fibonacci(c, quit chan int) {
x, y := 0, 1
for {
select {
case c <- x:
x, y = y, x+y
case <-quit:
fmt.Println("quit")
return
}
}
}
func main() {
c := make(chan int)
quit := make(chan int)
go func() {
for i := 0; i < 10; i++ {
quit <- 0
fmt.Println(<-c)
}
}()
fibonacci(c, quit)
}
Exercise: Equivalent Binary Trees
判断二叉树的先序遍历序列是否相同,实现是起两个 goroutine 先序遍历二叉树,通信使用各自的 buffer_size = 1 的 channel,
然后主 goroutine 循环 pop channel 里的数据进行比对,不算难,先序遍历的写法想了会儿2333333
package main
import "golang.org/x/tour/tree"
// Walk walks the tree t sending all values
// from the tree to the channel ch.
func Walk(t *tree.Tree, ch chan int) {
walk(*t, ch)
close(ch)
}
func walk(t tree.Tree, ch chan int) {
if t.Left == nil && t.Right == nil {
ch <- t.Value
return
}
if t.Left != nil {
walk(*t.Left, ch)
}
ch <- t.Value
if t.Right != nil {
walk(*t.Right, ch)
}
}
// Same determines whether the trees
// t1 and t2 contain the same values.
func Same(t1, t2 *tree.Tree) bool {
ch1, ch2 := make(chan int, 1), make(chan int, 1)
go Walk(t1, ch1)
go Walk(t2, ch2)
for {
t1v, ok1 := <-ch1
t2v, ok2 := <-ch2
if ok1 && ok2 {
if t1v != t2v {
return false
}
} else if ok1 || ok2 {
return false
} else {
break
}
}
return true
}
func main() {
println(Same(tree.New(21), tree.New(21)))
}
sync.Mutex
mutual exclusion: 互斥,用来控制同一时间只有一个 goroutine 访问同一个变量- go 提供了
sync.Mutex以及lock/unlock方法用来锁代码块
Exercise: Web Crawler
- 并发爬取
- 一个地址只抓一次
要求如上,不算难也不算简单,开始没想到要修改 Crawl 的函数签名,想了好一会儿,后来发现增加一个 channel 参数可破
package main
import (
"fmt"
"sync"
)
type Fetched struct {
v map[string]int
mux sync.Mutex
}
func (f *Fetched) add(key string) {
f.mux.Lock()
defer f.mux.Unlock()
f.v[key]++
}
func (f *Fetched) in(key string) bool {
f.mux.Lock()
defer f.mux.Unlock()
_, ok := f.v[key]
return ok
}
// Crawl uses fetcher to recursively crawl
// pages starting with url, to a maximum of depth.
func Crawl(url string, depth int, fetcher Fetcher, ch chan string) {
// TODO: Fetch URLs in parallel.
// TODO: Don't fetch the same URL twice.
// This implementation doesn't do either:
defer close(ch)
if ok := fetched.in(url); ok {
return
}
if depth <= 0 {
return
}
body, urls, err := fetcher.Fetch(url)
fetched.add(url)
if err != nil {
ch <- err.Error()
return
}
ch <- fmt.Sprintf("found: %s %q\n", url, body)
result := make([]chan string, len(urls))
for i, u := range urls {
result[i] = make(chan string)
go Crawl(u, depth-1, fetcher, result[i])
}
for i := range result {
for s := range result[i] {
ch <- s
}
}
return
}
func main() {
ch := make(chan string)
go Crawl("https://golang.org/", 4, fetcher, ch)
for v := range ch {
print(v)
}
}
type Fetcher interface {
// Fetch returns the body of URL and
// a slice of URLs found on that page.
Fetch(url string) (body string, urls []string, err error)
}
// fakeFetcher is Fetcher that returns canned results.
type fakeFetcher map[string]*fakeResult
func (f fakeFetcher) Fetch(url string) (string, []string, error) {
if res, ok := f[url]; ok {
return res.body, res.urls, nil
}
return "", nil, fmt.Errorf("not found: %s", url)
}
type fakeResult struct {
body string
urls []string
}
var fetched = Fetched{v: make(map[string]int)}
// fetcher is a populated fakeFetcher.
var fetcher = fakeFetcher{
"https://golang.org/": &fakeResult{
"The Go Programming Language",
[]string{
"https://golang.org/pkg/",
"https://golang.org/cmd/",
},
},
"https://golang.org/pkg/": &fakeResult{
"Packages",
[]string{
"https://golang.org/",
"https://golang.org/cmd/",
"https://golang.org/pkg/fmt/",
"https://golang.org/pkg/os/",
},
},
"https://golang.org/pkg/fmt/": &fakeResult{
"Package fmt",
[]string{
"https://golang.org/",
"https://golang.org/pkg/",
},
},
"https://golang.org/pkg/os/": &fakeResult{
"Package os",
[]string{
"https://golang.org/",
"https://golang.org/pkg/",
},
},
}
完
刷完,最后一节是扩展阅读,感觉 go 的文档化还是做得很好的,分类清晰,有张有弛,这里挑几个有意思的
对于并发编程模型
- Google I/O 2012 - Go Concurrency Patterns
- Google I/O 2013 - Advanced Go Concurrency Patterns
- Codewalk: Share Memory by Communicating
对于 web 开发
以及对于 go 函数式编程