直播课首页课程排序算法
2017-09-11
简介
最早我们的课程首页是用的一个活动页面,人工运营,后来课越来越多,人工运营成本太高,加上首页改版,所以决定让课程列表自动排序。
然而,需求里只写了一句:

按照以往的经验,这个锅算是丢给开发了,本着尽快上线的原则,我这边只能先搞一个排序,然后根据产品那边的反馈再进行调整吧。
新首页分析
这是新的课程首页:
最上面是一个大 logo,接下来是我的课程的一个跳转,然后是一个横滑的运营 banner 位置。
接下来是即将开课的横滑的位置,取最近未开始的十节课程,再下来是最新上架,按照创建时间逆序的十节课程,
(当然这里默认是新创建的课程开课时间也是最晚的),最下面就是这里要讲的按照一定规则排序的全部课程。
这里做一个分析,首先看下销量的排序原则,不考虑站外的影响因素,在站内给予相同曝光,卖的越多说明受众范围越大, 所以销量的排序原则就是销量越高值越大。
然后是时间的排序原则,按照以往的数据,而且本身这个产品给用户的印象是直播课,在未开课之前的单量占了绝大多数, 回看的售卖是相当小的一部分,所以未来课程的时间权重值的计算方式和已上过的课程的时间权重值计算方式应该有所区分。 并且未来课程的值域应该整体高于已上课程的权重的值域。
未来课程排序
在未来课程中,即将开始的课程在上面有一个横滑的位置露出;新创建的课程在上面也有一个横滑位置露出;所以应该给这两部分 尽量小的权重,给中间那一部分的未开始的课程尽量大的权重。
已上课程排序
在已上过的课程中,刚结束的课程因为已经从 最新上架 到 全部课程前面位置 到 即将开课,给了充足的曝光,所以这部分
的权重应该相对较小;然后对于中间的课给予较高权重,对于最早开始的课给予较低权重。
综合排序
因为期望这个列表是变化的,所以随着时间每个课程都要经历: 最新上架(极高曝光) -> 全部课程(高曝光) -> 即将开课(极高曝光) -> 刚结束(较低曝光) -> 结束有一段时间了(低曝光) -> 结束很久了(较低曝光),这样能保证每个课程在首页都有充足的曝光, 并且一直有新的课程流入。
最后因为是销量和开课时间的综合排序,上面已经讲了主要售卖都在未开始的课程里,所以时间的权重应该高一些,但是销量同时也反映着 课程内容的受众群体大小,所以时间权重会比销量权重高一些,但是差别不会很大。这样的话前面的位置的大部分会留给未开始的课程, 但是对于已经上过的较受欢迎的课程也会在前面有一部分位置。
实现方式
销量权重
这个就比较简单了:
时间权重
上面讲了时间分为两部分,每部分的权重值都是中间高,两边低的形状,所以这里用了两个余弦函数来拟合,每个余弦函数都是一个周期, 然后未来课程的值域整体应该比已上课程的值域要高一些,所以这里的计算方式如下
图像大概是这个样子:
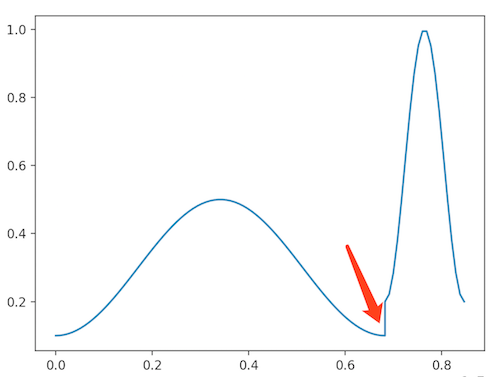
箭头位置就是此刻的时间戳,两个函数的值域分别是 和
课程rank
时间权重给了 , 销售权重给了
代码示例
import time
import datetime
import numpy as np
def calculate_time_weight(time_array):
now = datetime.datetime.now()
now_timestamp = time.time()
past, future, timestamp_array = 0, 0, []
for t in time_array:
timestamp = time.mktime(t.timetuple())
timestamp_array.append(timestamp)
if t > now:
delta = timestamp - now_timestamp
if delta > future:
future = delta
else:
delta = now_timestamp - timestamp
if delta > past:
past = delta
result = []
for t in timestamp_array:
if t > now_timestamp:
rad = 2 * np.pi * ((t-now_timestamp)/future)
result.append(0.4 * np.cos(rad - np.pi) + 0.6)
else:
rad = 2 * np.pi * ((now_timestamp-t)/past)
result.append(0.2 * np.cos(rad - np.pi) + 0.3)
return result
def calculate_sale_weight(sale_array):
max_sale = float(max(sale_array))
return [i/max_sale for i in sale_array]
输入是数组,输出为一一对应的各自权重数组。
总结
从接活到开发完成大概也就两天时间,中间还有些其他的业务逻辑,但是真正上到线上感觉还是有很多不足,而且感觉思维上还有些冲突, 比如:
- 老用户占比多,买过的课不会再买,上过的课卖的多,放前面占坑没意义
- 目的主要是拉新,老用户喜欢的所以新用户很大可能是喜欢的这个假设是合理的
- 十个课程,刚好交界地方的顾虑不到
不过处于成本考虑,个性化或者更复杂的算法需要算法部门同事开发,这个是当前相对较好的解决方案。而且目前量相对较少,先跑一段 时间看看数据吧。