记一次 flink 接 kafka 消息丢失的排查
2019-03-25
今年我司上了 flink,然后主要是咱来推这个事情,不过之前作为 python 后端业务逻辑狗突然转 jvm 大数据岗位确实吃了不少苦头。之前我们线上的 ETL 任务都用 spark 在凌晨跑,任务越来越多都放凌晨跑,spark 集群在量大的时候有点撑不住,于是看看能不能用 flink 来做这个事情。
当然是能的,flink 的流处理+EOS 特性很适合做 ETL 这种任务。
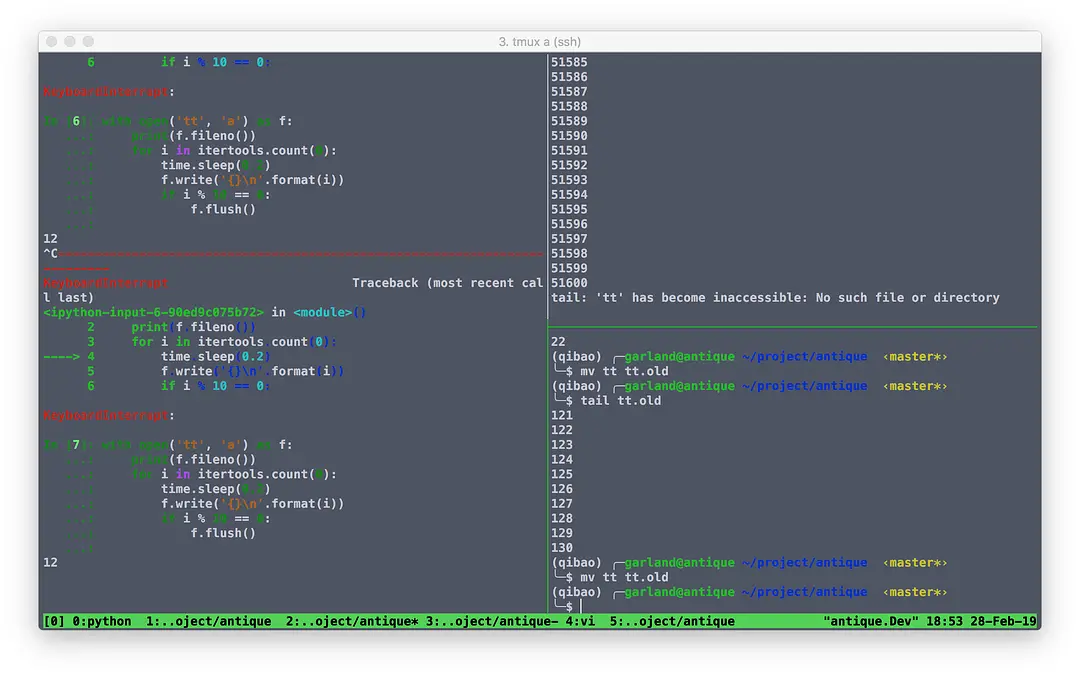
先说一下我们的打点日志收集架构,打点日志在 nginx 层进行转发,使用 logrotate 每 5 分钟切割一次,spark ETL 在每天的凌晨一点钟将前一天切割好的日志同步到 hive 里。也就是这个事情现在交由 flink 来实现,首先得把实时日志导入到 kafka 的消息队列,我们用的是 kafkacat,然后使用 flink-connector 消费 kafka 消息队列 sink 到 parquet 文件中,代码没多久就写好了,线上跑了几天,然后对比数据就出问题了。
首先是发现丢数据了,因为我是以小时为单位来比较,所以把一天拆成 24 个小时,看了下 hive 里的数据和 parquet 文件里的数据,发现丢的数据和日志的量走势是一致的,而且丢的比例基本都在 1/10000,然后把差的的这部分数据拿出来看了下,发现时间很迷:
 2019-02-26 12:00:00 – 2019-02-26 13:00:00 丢失的数据
如上图所示
2019-02-26 12:00:00 – 2019-02-26 13:00:00 丢失的数据
如上图所示
这个时候首先怀疑自己 flink job 这边的逻辑是不是有问题,就读取了原始日志文件数据源,后面跟同样的逻辑,发现没丢数据,然后把 job 里的 parquet sink 和多余的 filter flat_map 啥的改为计数接回 kafka 数据源看了看发现还是丢数据,这个时候就有点怀疑是 kafka 的问题了,后面写了个 python 脚本消费 kafka 做 count 发现 python 也丢,说明数据从 kafka 出来的时候就已经少了。
kafka 出来少了有两种情况,一种是 offset 有问题,另一种是进去的时候就少了。先看第一种,首先发现任务有 exception 并且有重试记录,然后就把任务里的 bug 修了,并且加了资源防止被 yarn 杀掉,然后观察了下 flink metrics 各个算子输入和输出的计数以及 exception 和 restart log,发现监控没什么问题,然后想是不是 flink checkpoint 和 kafka-connector 这边 consumer 的 offset commit 有冲突,我们用的是 flink 1.7 以及 kafka011,配置就只配置了 enableCheckpointing ,查了下文档发现这个配置没毛病,结合上面👆的测试就怀疑是不是数据进去的时候就已经少了。
row_log 往 kafka 导是我司 sa 配置的,然后就和他对了下,发现确实是入的问题,问题是这样的,我司的 nginx log 往 kafka 写是这么实现的:
tail -n0 -F row_log_path | stdbuf -oL kafkacat -q -P -b 'broker' -t 'topic'
然后这个 row_log_path 会被 logrotate,我们用的是 create 方案,也就是 row_log 首先会被 mv,然后再创建一个新的同名的 row_log 文件继续写入,首先来看一下 tail 的 -F 参数,linux 下的含义等同于 –follow=name –retry,也就是根据文件名来监控,并且在文件不存在的时候进行重试,而在 Linux 中操作文件都是通过文件描述符,mv 之后不影响文件描述符,所以 mv 之后,新的文件创建之前中间这段时间内写入的日志 tail -F 是拿不到的,也就是刚好每五分钟丢一次数据。
怎么解决呢?可能需要实现一个新的 tail 在监控老文件的 fd 的同时监控该目录下新创建的同名文件的 fd,等我不日实现一个。
另外,Mac 的 tail 是 BSD 的 tail,和 linux 的 tail 实现不一样,Mac 的 tail -F 在 mv 之后能继续输出并且在该目录下新的同名文件创建后也能继续输出,参数解释如下
-f The -f option causes tail to not stop when end of file is reached, but rather to wait for additional data to be appended to the input. The -f option is ignored if the standard input is a pipe, but not if it is a FIFO.
-F The -F option implies the -f option, but tail will also check to see if the file being followed has been renamed or rotated. The file is closed and reopened when tail detects that the filename being read from has a new inode number. The -F option is ignored if reading from standard input rather than a file.
看一下 Linux 的 tail
-f, --follow[={name|descriptor}]
output appended data as the file grows; -f, --follow, and --follow=descriptor are equivalent
-F same as --follow=name --retry
看到 Linux 的 tail -f 是可以接 fd 的,也就是按照手册 tail -n0 –follow=descriptor log_file 在 mv 之后也是可以输出的,试了下发现不行,问了下朋友发现可以,对比了下版本,8.21 的 tail 就是不行,至少 8.28 往上的 tail 是可以的,看了下 tail 的 release note 发现 tail 在 8.25 以后改用 inotify 来实现,后面就没有再细看了。
参考朋友的测试:
REF:
- logrotate 的食用方法
- Inotify 机制详解
- 朋友 && 我司SA && man 手册