Stanford Machine Learning Note
2015-04-07
课程地址:Machine Learning
单变量线性回归
建立模型
课程里面给的栗子是根据已有的数据集通过房间面积预测房屋售价。首先建立一个假设,它的输入是房屋的面积,然后输出是预测的价格,然后定义这个假设(Hypothesis)为
准则函数
之前已经定义了一个假设函数,现在的目的是要找出一条直线能够很好地拟合数据集,也就是要找到最合适的 使它 的值和数据集中的值很接近。表示的是样本集中的第组数据,所以就可以定义如下的准则函数:
目标是找到合适的和 使最小,其实里面的那个2要不要都可以的,除以2是为了后面求导比较方便。然后准则函数叫做均方误差函数,它的的图像是一个平滑的碗状图像,有全局最优解,求这个解的话就要用到梯度下降法了
梯度下降法
学过高数都知道,梯度方向是函数增长最快的方向,那么负梯度方向就是函数下降最快的方向。对于栗子:
步骤如下:
- 从任意一个点开始,可以取
- 改变的值,使越来越小,直到收敛
但是呢,根据初始值选取的不同,可能只会得到局部最优解,这个问题的话,后面再讲。 而对于每次迭代的值的更新,使用梯度下降法就是
其中是每次迭代的步长,扩展开就是:
其中,如果太小的话,收敛速度会很慢,如果太大的话可能不会收敛,而且,也没有必要动态地修改,因为随着迭代,每次减小的步长会越来越小。
对于目标函数,有:
现在回到之前说到的根据初始值的不同容易收敛到局部最优解的问题。其实,线性回归的准则函数一般都是一个碗状的函数,这种函数叫凸函数,这种函数没有局部最优解,只有一个全局最优解,所以在使用梯度下降法处理这类准则函数的时候不用担心会收敛到局部最优解的问题。
对于这个栗子中使用的算法,又叫做批量梯度下降法(Batch Gradient Descent),就是说,每一次迭代都会用到训练数据集的所有数据。对于求解的最小值有另一种方法Normal Equations,不需要遍历所有训练数据集.
多变量线性回归
之前举的栗子是通过房屋面积预测价格,现在除了面积有了其他的特征,比如房间数量,楼层,屋子的年龄这些特征,所以现在的训练数据集从一维变成四维的了。这里,使用表示特征的数量,表示输入的样本,比如在这里是一个4*1的矩阵,表示第训练样本的第个特征,在这里.所以现在的假设就变成了:
现在扩展到个特征:
为了方便,这里定义.所以上式就可化为
然后现在准则函数就变成了:
梯度下降法
因为每个特征的数据的取值范围不同,所以如果直接拿过来计算肯定是会出现奇怪的事情的,所以在运算之前,得对数据做一下Feature Scalling,也就是把每个特征的数据归一化到相同的区间,一般来说是或者,这里给个公式:
是这个特征的均值,这个处理出来的范围是
评价梯度下降法正确运行的一点是随着迭代次数的增加,的值是越来越小的。如果算法不能正常工作的话,试着把减小一点,一般来说,对于可以从
Normal Equation
之前使用的梯度下降法是通过迭代不断修改直到的最优解。而Normal Equation是通过计算直接得到合适的值,现在回到之前的栗子:
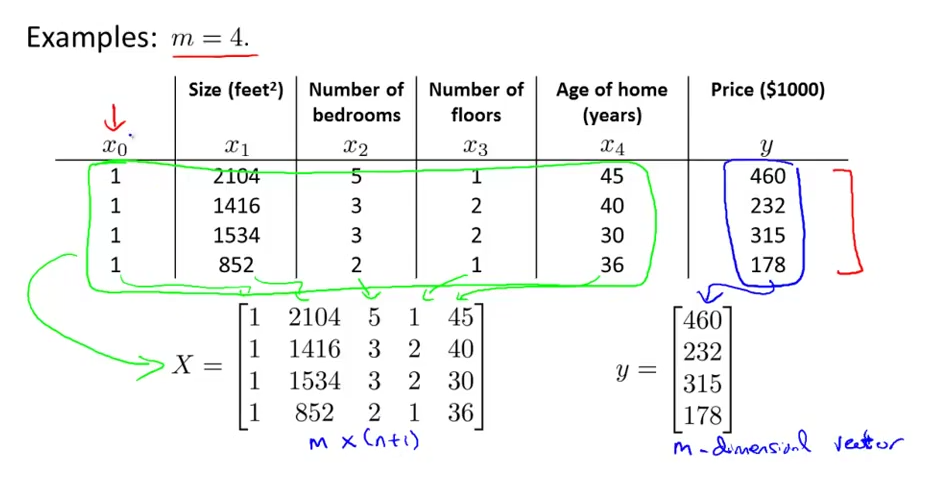 如图所示,是为了计算方便加的一列,是特征矩阵,是每组数据的类标(也就是值),然后用下面的公式可以求解准则函数最优解对应的值:
如图所示,是为了计算方便加的一列,是特征矩阵,是每组数据的类标(也就是值),然后用下面的公式可以求解准则函数最优解对应的值:
那么问题来了,如果是奇异矩阵怎么办?有下面几个办法
- 在matlib和Octave里可以使用pinv()求解伪逆矩阵
- 去掉样本中冗余的特征(比如和线性相关)
- 如果的话,去掉一些特征
然后,对于使用Normal Equation方法求解的时候,Feature Scalling是没有必要做的,然是如果使用梯度下降的话,是一定要做Feature Scalling的
对比
现在有个训练样本,个特征,什么时候该用梯度下降,什么时候用Normal Equation呢? 先说一下梯度下降法:
- 优点:特别大的时候效率很高
- 缺点:需要自己选择;需要多次迭代
Normal Equation:
- 优点:不需要选择;不需要迭代
- 缺点:需要计算比较花时间;比较大的时候很慢
Logistic Regression
假设现在有一个分类问题:根据肿瘤体积预测它是良性的还是恶性的,如下图的训练样本:
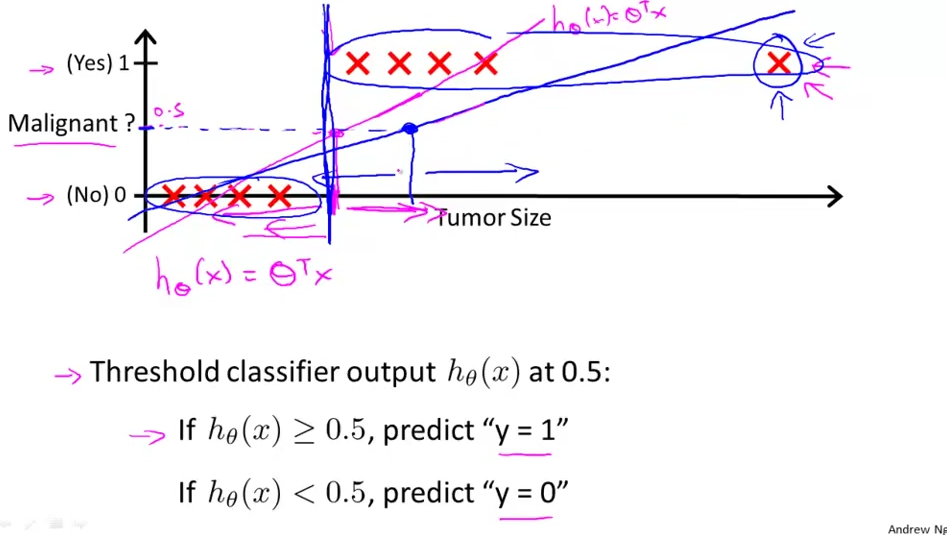 上面的一行是恶性肿瘤,下面的一行是良性肿瘤,对于分类问题,如果使用之前的线性回归的话,就不能很好地满足图中的要求,所以一般在这种分类问题中不使用线性回归。
上面的一行是恶性肿瘤,下面的一行是良性肿瘤,对于分类问题,如果使用之前的线性回归的话,就不能很好地满足图中的要求,所以一般在这种分类问题中不使用线性回归。
对于一个二分类问题,它的解集永远在中,对于线性回归它的值可能或者,像上图那样。所以引入Logistic Regression:用来处理分类问题
Hypothesis Representation
其中就是Sigmoid function或者Logistic function,所以Logistic function就变成了:
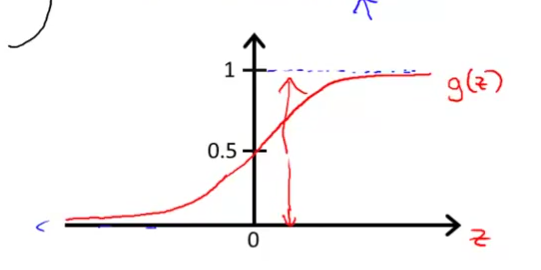
这个就是它的图像了,值域在,与轴的交点是,满足之前的要求的。
Decision Boundary
首先想下怎样正常工作?
- 当的时候,即
- 当的时候,即
也就是说,需要找到一个判别面把样本集分成两部分,对于复杂的判别面,可能就会用到复杂的多项式来处理了。
准则函数
先说一下目的:现在有训练样本,其中,,,有:
现在的问题是,如何选择参数?
这个评价函数的含义就是:如果预测值和真实值相同的话,评价函数的值就是0,不同的话,评价函数的值就是无穷大。
Simplified Cost Function and Gradient Descent
和和上面的一样,而且对于的值,要么是0要么1,现在对进行简化:
所以,扩展开就变成了下面的样子:
使用梯度下降法更新求解的话:
Advanced Optimizetion
比如下面几个
- Conjugate gradient
- BFGS
- L-BFGS
这些算法的优点有:1.不用手动选择;2.一般来说比梯度下降法要快的。缺点当然也有了,它们都比较复杂。
多分类问题
Regularization
过拟合
过拟合指的是在样本有很多特征的时候,为了追求对训练样本过高的拟合率,建立了复杂的模型去训练,并且训练样本数据拟合地特别特别好,但是对于测试集的效果很糟糕。